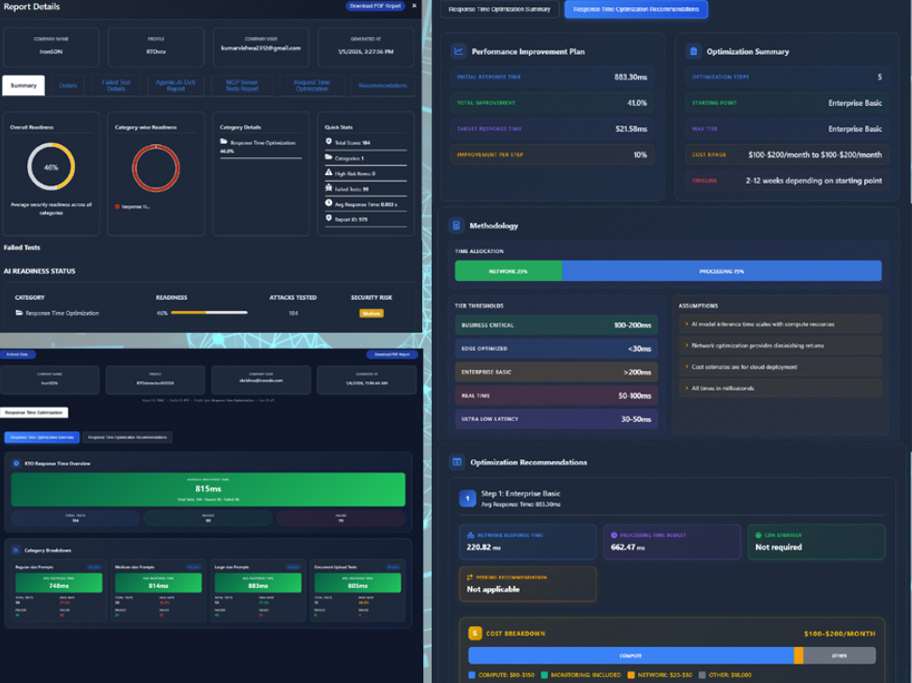
WhiteHaX OptimalAI Testing is a comprehensive performance testing and optimization service designed to ensure business-critical AI applications deliver fast, reliable, and consistent user experiences. As AI-powered applications become core to enterprise workflows, response time, scalability, and infrastructure efficiency directly impact customer satisfaction, productivity, and operational cost.
OptimalAI Testing evaluates AI deployments under real-world and extreme conditions, measuring response times, system behavior, and infrastructure limits. Based on these insights, the service delivers detailed, actionable optimization recommendations across compute, memory, instance sizing, networking, and quality-of-service layers—enabling organizations to continuously optimize AI performance as usage grows.
Businesses can use OptimalAI Testing periodically or as part of pre-production validation to ensure their AI systems remain performant, resilient, and cost-efficient.
Key Objectives
OptimalAI Testing evaluates AI system behavior across a wide spectrum of prompt sizes, structures, and response-generation patterns to accurately reflect real-world usage and edge cases.
This testing evaluates AI performance during document ingestion and knowledge-processing workflows, which are critical for RAG, summarization, analytics, and enterprise AI use cases.
OptimalAI Testing simulates extreme load and adversarial traffic patterns to evaluate AI system resilience, security posture, and cost stability under stress.
OptimalAI Testing provides holistic response-time measurement across all test scenarios, capturing both average and tail latency.
AI Abuse & Cost Risk Analysis
Modern AI deployments face not only performance risks but also abuse-driven cost escalation and service degradation. WhiteHaX OptimalAI Testing includes a dedicated AI Abuse & Cost Risk assessment to identify how malicious or unintended usage patterns can impact availability, performance, and operating cost.
Risk areas analyzed include:
Outcomes:
Test Types Mapped to Business Impact & KPIs
| Feature | Business Impact | Key KPIs |
|---|---|---|
| User Prompt Size & Response Testing |
|
|
| Document Upload & Processing Testing |
|
|
| Heavy Load & DoS-Style Stress Testing |
|
|
| AI Abuse & Cost Risk Testing |
|
|
Following testing, WhiteHaX delivers full-scale, actionable optimization recommendations tailored to the specific AI deployment architecture.
Each OptimalAI Testing engagement includes:
WhiteHaX OptimalAI Testing enables organizations to confidently deploy and scale AI applications with predictable performance and exceptional user response times. By combining rigorous response-time measurement with expert optimization recommendations, businesses gain the insight and guidance needed to keep AI systems fast, resilient, and cost-efficient—today and as demands grow.
Proprietary and copyrighted material of IronSDN, Corp. ©️ Copyright 2022. All rights reserved.
For more information, visit www.WhiteHaX.com